CloudTrail日志转换为Parquet格式
CloudTrail默认往s3里存放日志是json格式:
随着里面的日志越积越多,使用athena对cloudtrail日志进行查询是非常耗时的,特别是没有分区的字段,比如要对历史的AK进行访问IP来源的审计,需要扫全部数据。如果数据量达到几T级别,基本上查不出来。
我们将使用 Glue ETL将CloudTrail JSON日志批量转换为Parquet格式,以加速Athena查询性能,特别适用于AK/SK的IP审计需求。
前置条件:CloudTrail日志已存储在S3中
创建目标S3存储桶
# 创建存储Parquet格式日志的桶
aws s3 mb s3://cloudtrail-parquet-logs-$(date +%s)
# 记录桶名,后续步骤会用到
export PARQUET_BUCKET="cloudtrail-parquet-logs-1762827805"
echo "Parquet bucket: $PARQUET_BUCKET"
创建IAM角色给Glue使用
# 创建信任策略文件
cat > glue-trust-policy.json << EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
# 创建IAM角色
aws iam create-role \
--role-name GlueCloudTrailETLRole \
--assume-role-policy-document file://glue-trust-policy.json
# 附加必要的策略
aws iam attach-role-policy \
--role-name GlueCloudTrailETLRole \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
# 创建S3访问策略,需要将YOUR-CLOUDTRAIL-BUCKET桶名做替换
cat > glue-s3-policy.json << EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::YOUR-CLOUDTRAIL-BUCKET/*",
"arn:aws:s3:::$PARQUET_BUCKET/*",
"arn:aws:s3:::YOUR-CLOUDTRAIL-BUCKET",
"arn:aws:s3:::$PARQUET_BUCKET"
]
}
]
}
EOF
# 创建并附加S3策略
aws iam create-policy \
--policy-name GlueCloudTrailS3Policy \
--policy-document file://glue-s3-policy.json
aws iam attach-role-policy \
--role-name GlueCloudTrailETLRole \
--policy-arn arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):policy/GlueCloudTrailS3Policy
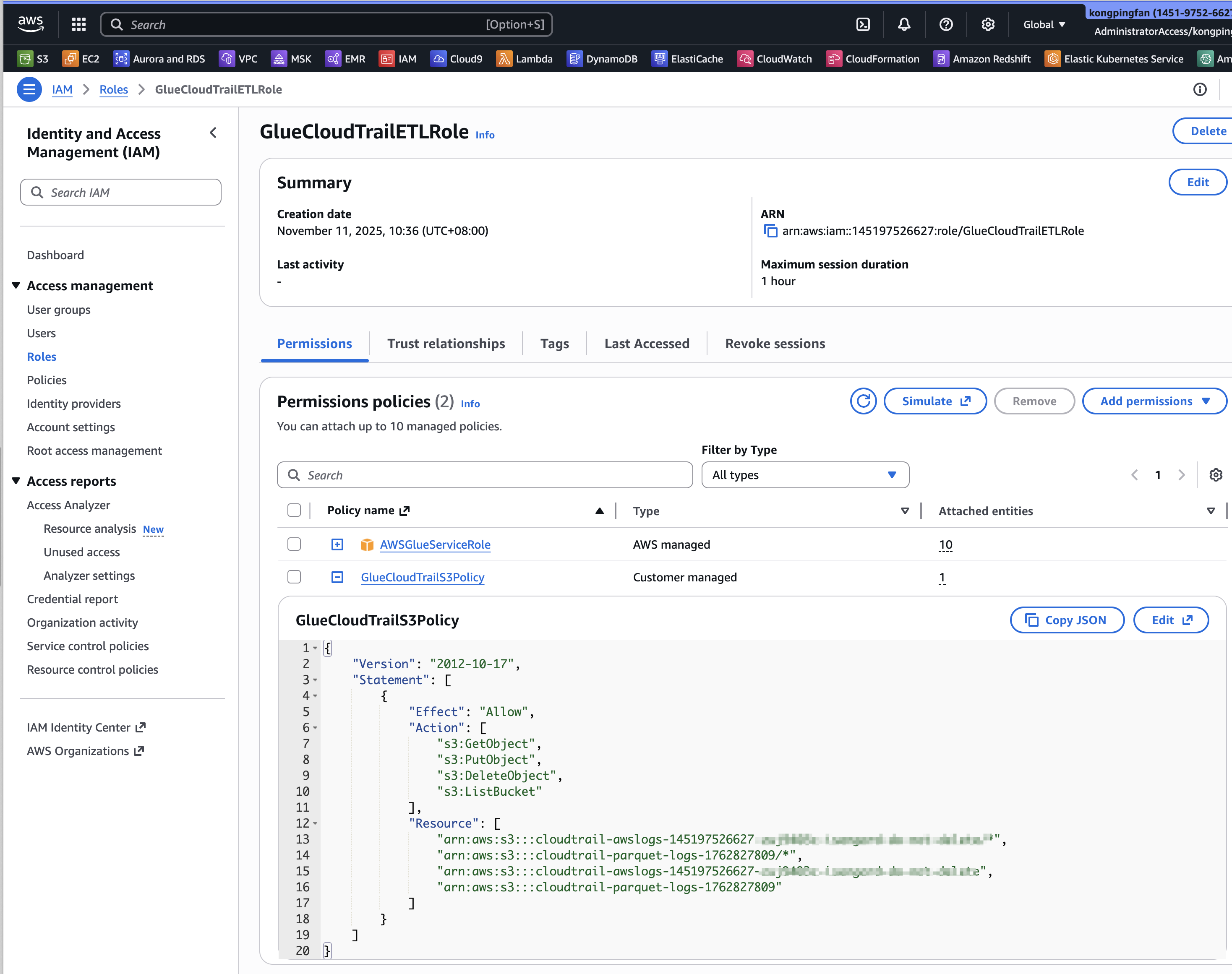
在iam里面检查这个role:
步骤5:创建Glue ETL作业
cat > cloudtrail-etl-script.py << 'EOF'
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import functions as F
from pyspark.sql.types import *
from datetime import datetime, timedelta
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'TARGET_BUCKET', 'SOURCE_BUCKET'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
schema = StructType([
StructField("Records", ArrayType(StructType([
StructField("eventTime", StringType()),
StructField("eventName", StringType()),
StructField("eventSource", StringType()),
StructField("awsRegion", StringType()),
StructField("sourceIPAddress", StringType()),
StructField("userAgent", StringType()),
StructField("requestID", StringType()),
StructField("eventID", StringType()),
StructField("errorCode", StringType()),
StructField("errorMessage", StringType()),
StructField("userIdentity", StructType([
StructField("type", StringType()),
StructField("accessKeyId", StringType()),
StructField("userName", StringType()),
StructField("arn", StringType()),
StructField("principalId", StringType())
]))
])))
])
end_date = datetime.now()
start_date = end_date - timedelta(days=3)
current = start_date
total = 0
while current <= end_date:
y, m, d = current.year, current.month, current.day
source = f"s3://{args['SOURCE_BUCKET']}/AWSLogs/*/CloudTrail/*/{y}/{m:02d}/{d:02d}/"
try:
df = spark.read.schema(schema).json(source)
df_records = df.select(F.explode("Records").alias("record")).select(
F.col("record.eventTime"),
F.col("record.eventName"),
F.col("record.eventSource"),
F.col("record.awsRegion"),
F.col("record.sourceIPAddress"),
F.col("record.userAgent"),
F.col("record.requestID"),
F.col("record.eventID"),
F.col("record.errorCode"),
F.col("record.errorMessage"),
F.col("record.userIdentity.type").alias("userIdentityType"),
F.col("record.userIdentity.accessKeyId").alias("accessKeyId"),
F.col("record.userIdentity.userName").alias("userName"),
F.col("record.userIdentity.arn").alias("userArn"),
F.col("record.userIdentity.principalId").alias("principalId")
).withColumn("year", F.lit(y)).withColumn("month", F.lit(m)).withColumn("day", F.lit(d))
count = df_records.count()
if count > 0:
output = f"s3://{args['TARGET_BUCKET']}/cloudtrail-parquet/year={y}/month={m}/day={d:02d}/"
df_records.coalesce(2).write.mode("overwrite").parquet(output)
total += count
print(f"{y}-{m:02d}-{d:02d}: {count} records")
except Exception as e:
print(f"{y}-{m:02d}-{d:02d}: Error - {str(e)}")
current += timedelta(days=1)
print(f"COMPLETED! Total: {total} records")
job.commit()
EOF
# 上传脚本到S3
aws s3 cp cloudtrail-etl-script.py s3://$PARQUET_BUCKET/scripts/
# 设置变量
PARQUET_BUCKET=""
SOURCE_BUCKET="xxx"
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
# 创建Glue作业(30 DPU配置)
aws glue create-job \
--name cloudtrail-to-parquet-etl \
--role arn:aws:iam::$ACCOUNT_ID:role/GlueCloudTrailETLRole \
--command '{
"Name": "glueetl",
"ScriptLocation": "s3://'$PARQUET_BUCKET'/scripts/cloudtrail-etl-script.py",
"PythonVersion": "3"
}' \
--default-arguments '{
"--TempDir": "s3://'$PARQUET_BUCKET'/temp/",
"--job-bookmark-option": "job-bookmark-enable",
"--enable-metrics": "true",
"--enable-spark-ui": "true",
"--spark-event-logs-path": "s3://'$PARQUET_BUCKET'/spark-logs/",
"--enable-job-insights": "true",
"--TARGET_BUCKET": "'$PARQUET_BUCKET'",
"--SOURCE_BUCKET": "'$SOURCE_BUCKET'",
"--conf": "spark.driver.memory=16g --conf spark.driver.maxResultSize=8g --conf spark.executor.memory=10g --conf spark.sql.shuffle.partitions=600"
}' \
--max-retries 0 \
--timeout 2880 \
--glue-version "4.0" \
--number-of-workers 30 \
--worker-type "G.1X" \
--region us-west-2
在glue控制台中可以找到这个job:
运行ETL作业
点击右上角的运行:
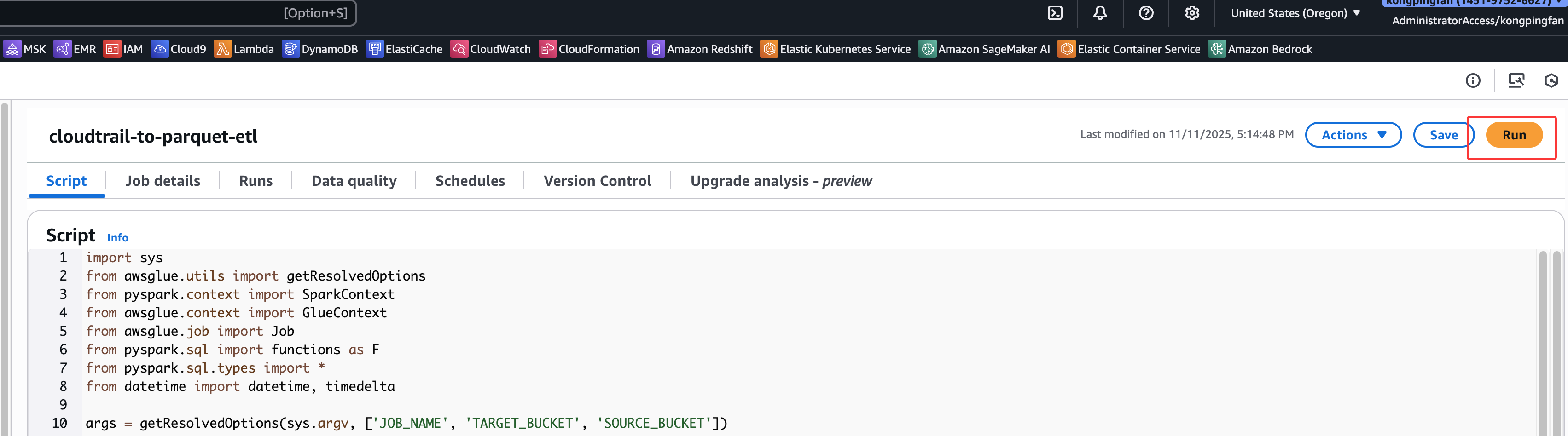
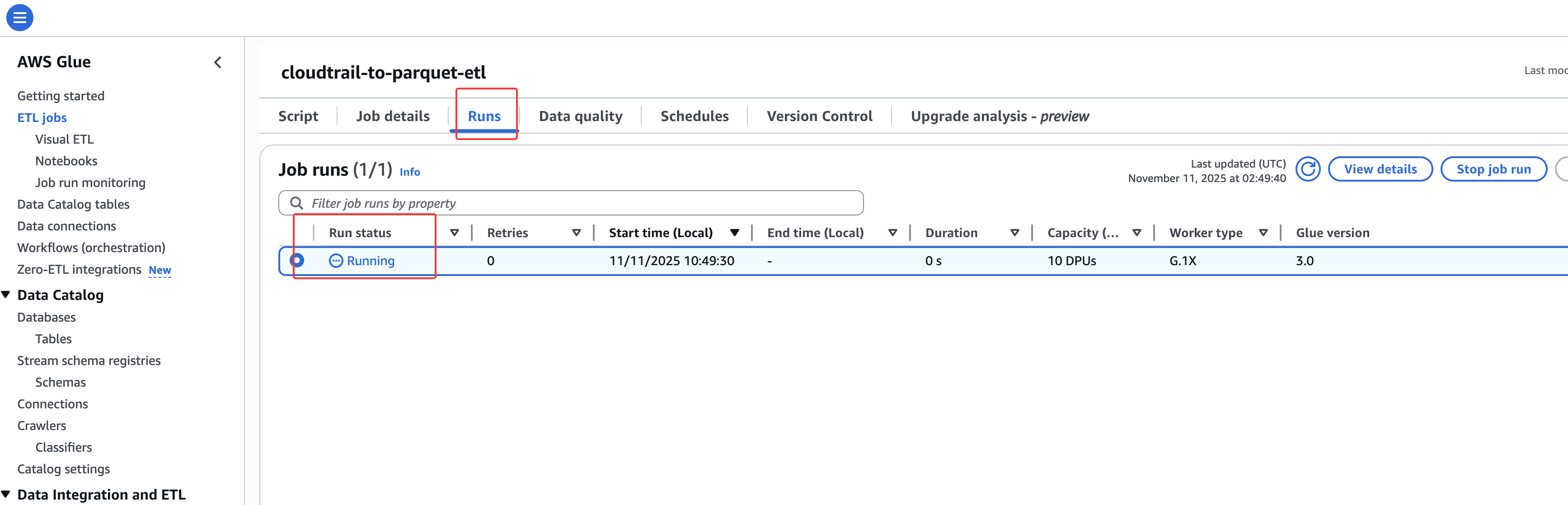
在Runs里面能找到运行的任务:
在Athena中创建Parquet表
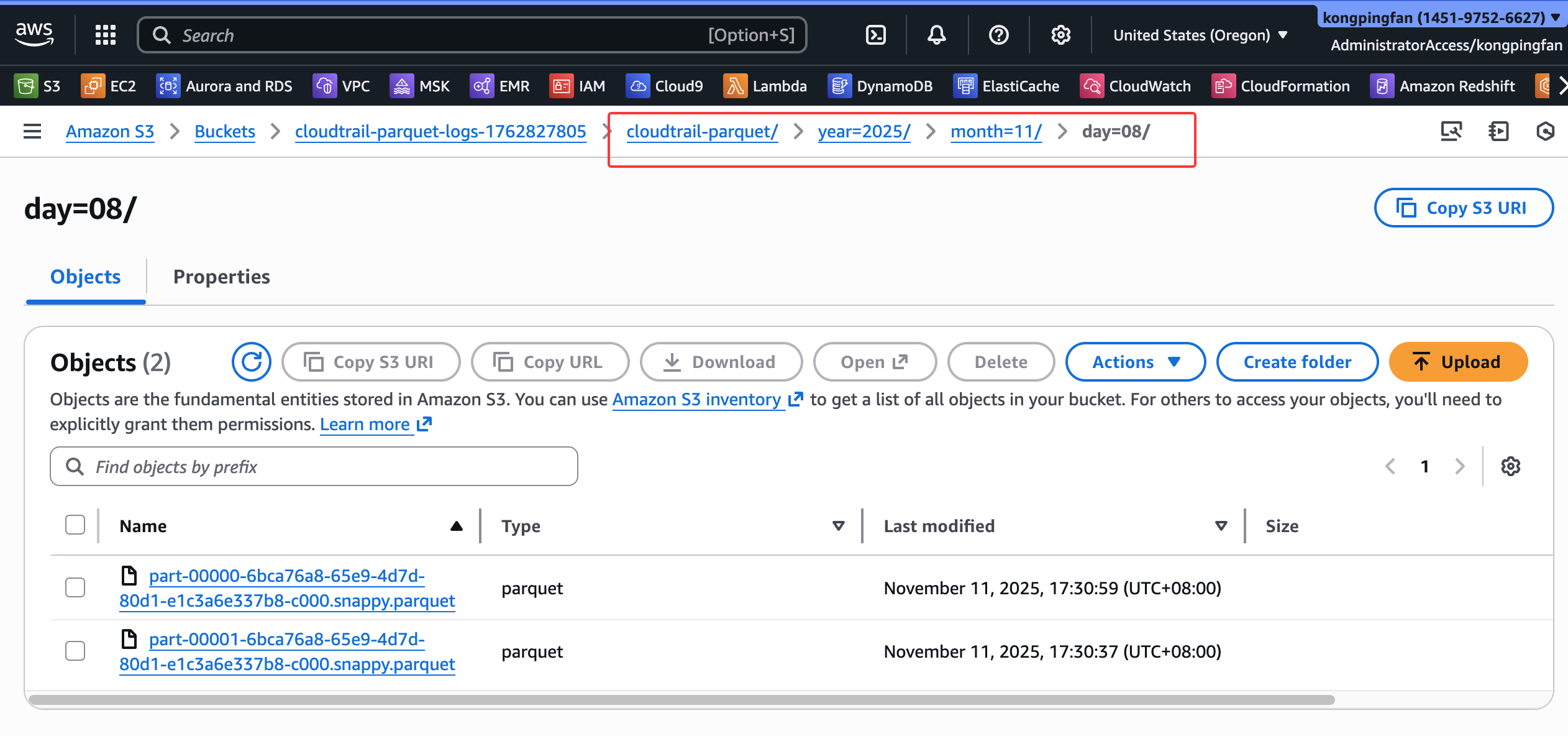
任务运行一段时间后,会在s3目录下生成parquet文件:
等任务运行结束后,在athena里建表:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS cloudtrail_db;
-- 创建表(包含完整字段),替换location路径为实际的桶
CREATE EXTERNAL TABLE cloudtrail_db.cloudtrail_logs (
eventTime string,
eventName string,
eventSource string,
awsRegion string,
sourceIPAddress string,
userAgent string,
requestID string,
eventID string,
errorCode string,
errorMessage string,
userIdentityType string,
accessKeyId string,
userName string,
userArn string,
principalId string
)
PARTITIONED BY (year int, month int, day int)
STORED AS PARQUET
LOCATION 's3://cloudtrail-parquet-logs-1762827805/cloudtrail-parquet/';
-- 加载分区
MSCK REPAIR TABLE cloudtrail_db.cloudtrail_logs;
注意: 替换为实际的桶名。
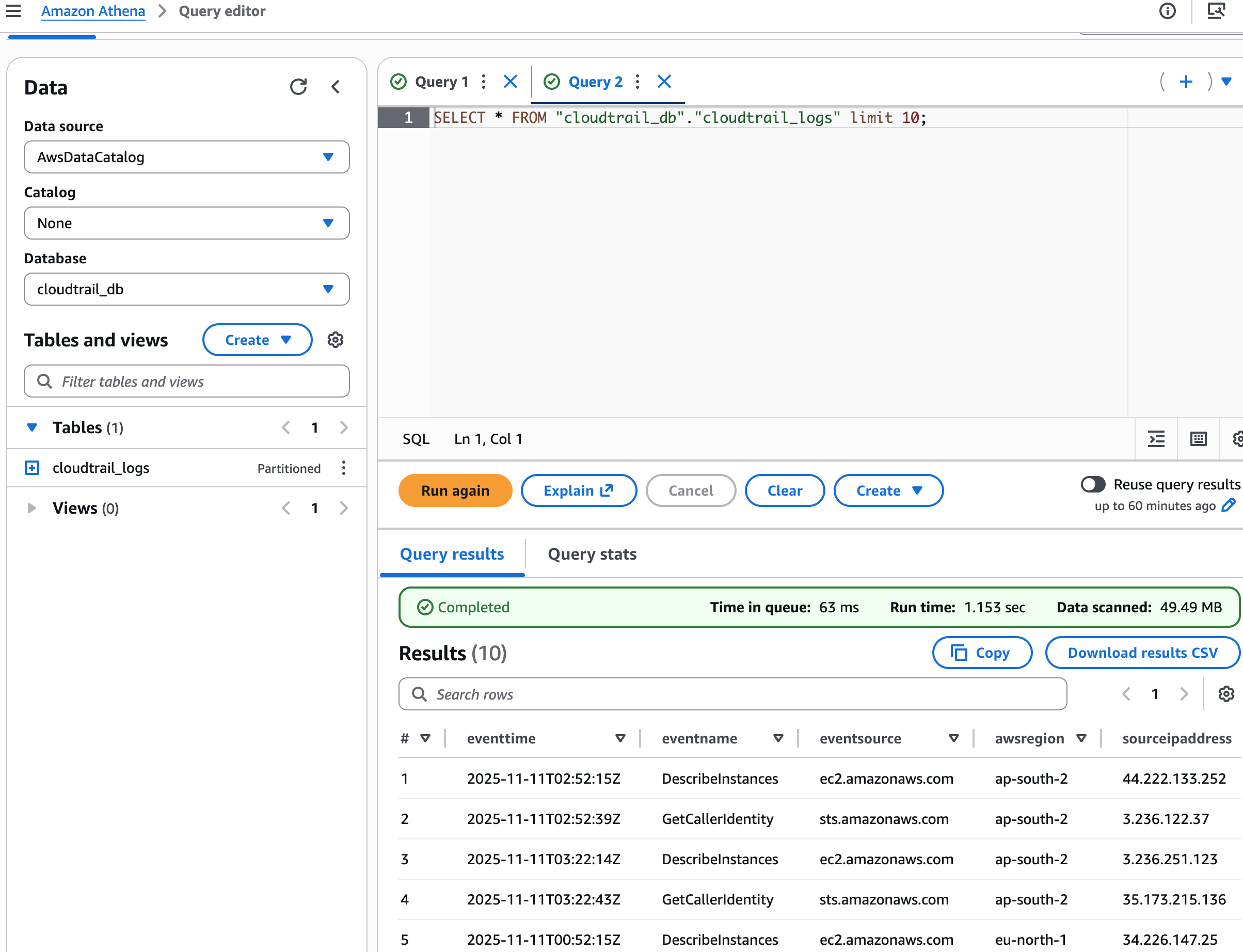
验证下能查到结果:
AK/SK IP审计查询语句
查询特定AK的所有访问IP
-- 查询某个AK访问的所有IP
sql
SELECT
sourceIPAddress,
COUNT(*) as access_count,
MIN(eventTime) as first_seen,
MAX(eventTime) as last_seen
FROM cloudtrail_db.cloudtrail_logs
WHERE year=2025 AND month=11
AND accessKeyId = 'AKIA...' -- 替换成你要查的AK
GROUP BY sourceIPAddress
ORDER BY access_count DESC;
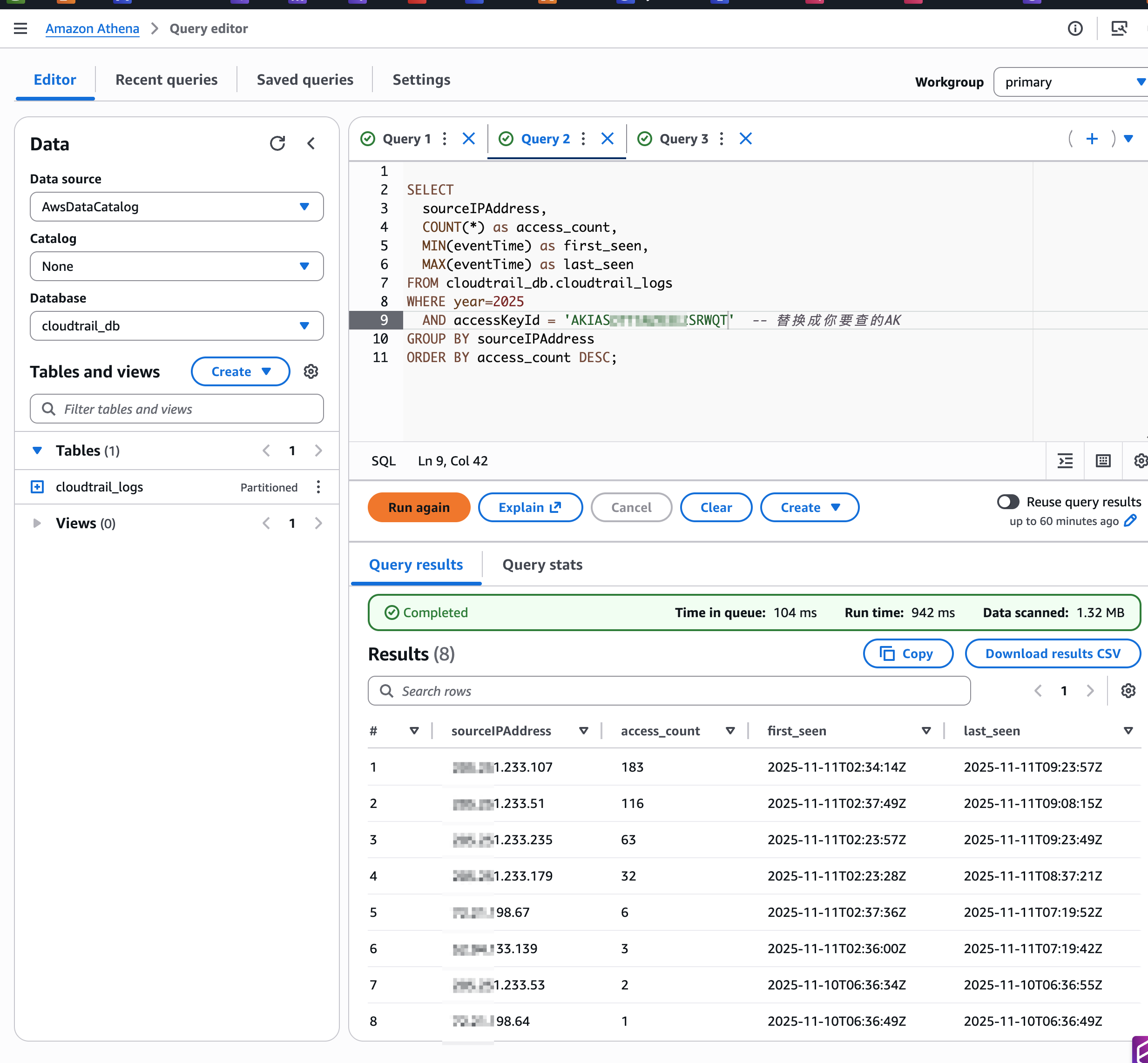
如果数据量不大,基本在秒级能查到结果。